Utilising Open-Source LLMs to Provide Advanced AI Solutions: Retrieval-Augmented Generation (RAG) in Action.
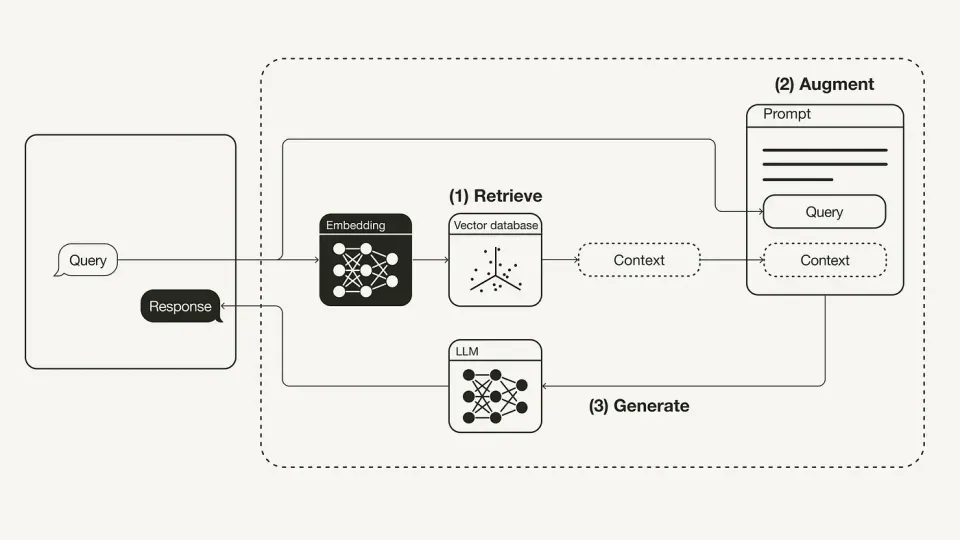
Here, we are going to see how to use open source LLMs to develop an RAG chatbot.
The primary drawback of LLMs, which is their inability to access data beyond the training data cut-off point, is addressed by RAGs. They provide dynamic solutions by integrating real-time data with LLMs. They are typically employed in document-question answering scenarios, where the user wants the model to respond based on their data, which may occasionally change, or on current data that was not utilised in training.
RAG and fine tuning are not the same, despite the common misconception. Retraining a pre-trained model to a specific dataset and updating a few model weights to ensure the model is also learned on fresh datasets is known as fine tuning. It lacks knowledge of real-time data and remains stagnant. RAGs, in comparison, are dynamic and do not adjust their weights in response to fresh data. In order to offer the model with context, such as prompts, RAGs extract pertinent information from the newly collected data.
Several important advantages of RAG include:
1. LLMs as engines of reasoning
2. Diminish delusions
3. Contextualization according to domain
4. Effectiveness and affordability
RAGs can be built using mostly any LLM, such OpenAI’s GPT-3, GPT-4 and other open source models as well. In this tutorial, we are going to see how to build RAG using open source LLMs. I’m using Mistral-7B-Model as my LLM, it requires HuggingFace authentication. It is open source but requires HuggingFace token ( which is free of cost :) ).
To start with lets install required libraries, in this tutorial we are using llamaindex as our framework
pip install llama-indexAs discussed earlier the open source model we’re using requires Hugging face authentication
huggingface-cli loginImport required libraries
from llama_index.llms import LlamaCPP
from llama_index.llms.llama_utils import messages_to_prompt, completion_to_prompt
from llama_index import VectorStoreIndex, SimpleDirectoryReader, ServiceContext
from llama_index.embeddings import HuggingFaceEmbeddingLoad LLM. There are several ways to load huggingface llms; in our case, we download the model and use the local Hugging Face model cache to run it on the hardware of our local system. The HuggingFaceInferenceAPI is another option that we have. It makes use of the same model, but does not save model in our cache it runs remotely on huggingface’s servers and is accessible to us via API. More on this can be found here .
llm = LlamaCPP(
model_url ="https://huggingface.co/TheBloke/Mistral-7B-Instruct-v0.1-GGUF/resolve/main/mistral-7b-instruct-v0.1.Q4_K_M.gguf",
model_path=None,
temperature=0.1,
max_new_tokens=256,
# llama2 has a context window of 4096 tokens, but we set it lower to allow for some wiggle room
context_window=3900,
generate_kwargs={"temperature": 0.3, "top_k": 50, "top_p": 0.95},
model_kwargs={"n_gpu_layers":-1},
messages_to_prompt=messages_to_prompt,
completion_to_prompt=completion_to_prompt,
verbose=True,
)To specify a file upload path using SimpleDirectoryReader, set the directory path where your files are located in the reader's configuration.
documents = SimpleDirectoryReader(input_files=["GenrativeAI_data.pdf").load_data()
Configure service context, it is a bundle of configurations that are required by LLM application during indexing / querying stage. you can find more about it here
embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5")
service_context = ServiceContext.from_defaults(chunk_size=256,llm=llm,embed_model=embed_model)
Load data into the index. Indexing documents is the key component in building an RAG application. you can find more about VectorStoreIndex in llamaindex here
index = VectorStoreIndex.from_documents(documents, service_context=service_context)Asking the model questions. After building the application, we now need to query the model. We employ A general interface called a query engine lets you ask questions about your data.
query_engine = index.as_query_engine()
while True:
query = input("Enter your query: ")
response = query_engine.query(query)
print(response)
Conclusion
Retrieval-Augmented Generation is a major breakthrough in artificial intelligence that improves the functionality and performance of open-source language learning models in a number of ways. RAG offers more accurate, relevant, and contextually appropriate solutions by fusing generative capabilities with retrieval methods, which makes it a useful tool for a variety of applications.